
I have been having to process and handle a wide variety of errors in the past few weeks, using Gaussian as well as Comet. Here are the conclusions we found if you ever run into similar errors.
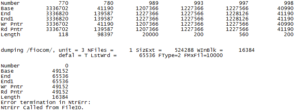
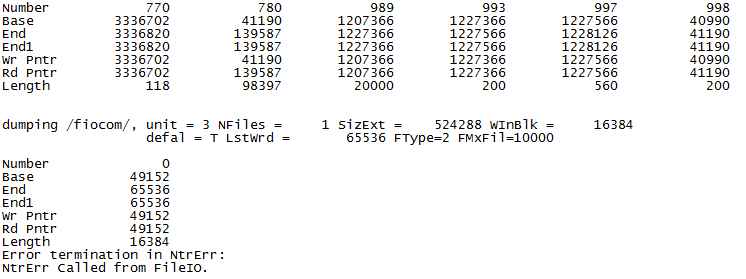
- FileIO error: This error was quite odd and took a lot of work to surpass. It was seen in at least three excited state optimization calculation output files but there was no other trend visible based on functional, basis set, or root number. This image is difficult to read but it essentially is a very long list of groups of numbers (like at the top), followed by “dumping /fiocom/ . . . . . Ntrerr called from FileIO”. After communicating with Gaussian Tech Support, they offered the advice of updating our Gaussian to the E version. To do this, go to the gaussian.sh file and where it says “module load gaussian,” correct it to “module load gaussian.09.E.01” and save. This error was due to a bug in the older version that we had been using, although it could have been circumvented using “opt=nolinear” or “guess=always” as a keyword. For this reason, we have been using version E of Gaussian for all further calculations.
- Python plots: In the energy_step_oscillator_plot.py script, I had difficult writing to the results file. Whenever I would run the module, the correct plot would pop up but then the results file would be empty (blank and 0KB). To see the proper results, make sure to refresh the folder in which the results.txt file is and also close the plot before opening the results. This is necessary if and only if your script reads to “results.close()” AFTER the plot order. If you simply move “results.close()” to before the plot instructions, this will not be an issue. Now, the results.txt file will close before the plots are displayed.
- There have been multiple different cases where jobs on comet required more memory. There would be a message towards the end of the prematurely terminated output file asking for more MW, which is a different unit of memory storage. I have been adding “%Mem=8GB” to almost all of my input .gjf files (as the first line) to ensure that the job doesn’t end early.
- If a job terminates otherwise but there is no clear explanation, this probably indicates that there was not enough wall time to perform the calculation entirely, so you should add more wall time or increase the number of processors you use for the calculation. To do so, you must change “nprocshared=1” to “nprocshared=8” and “ntasks-per-node=1” to “ntasks-per-node=8” or any number between 1 and 8, and also include “%nprocshared=#” at the top of your input file. This can show a dramatic decrease in the time necessary to perform certain calculations.
Nice summary of often frustrating errors and problems that come up in computational research (esp. with Gaussian and supercomputers).
1. For this reason we’re going to use version E for all calculations going forward.
2. For your read.close() comment, is it the case now that all of our scripts close the results.txt file before the plots are displayed? Makes total sense to me.
3. I think you mean “multiple cases where calculations needed more MEMORY” On comet, asking for 8GB should always be OK. (I think comet by default allocates ~6GB for a one core job and we don’t ever get near that as far as I know)
4. I think for your point 4 it could be a whole other post about how to submit gaussian jobs with multiple processors on comet. And of course the job can terminate for a lot of other reasons than just running out of wall time (as you have been seeing lately… )